Strategische Datenarchitektur für KI-Erfolg
Datenstrategie für KI
Entwickeln Sie eine zukunftssichere Datenstrategie, die Ihre KI-Initiativen zum Erfolg führt. Unsere strategischen Data Governance-Frameworks schaffen die Grundlage für leistungsstarke AI-Systeme und nachhaltigen Geschäftserfolg.
- ✓Strategische Data Governance für KI-optimierte Datenarchitekturen
- ✓Datenqualitäts-Management für hochperformante Machine Learning
- ✓Cross-funktionale Datenintegration für AI-driven Business Intelligence
- ✓Skalierbare Dateninfrastrukturen für Enterprise-AI-Transformation
Ihr Erfolg beginnt hier
Bereit für den nächsten Schritt?
Schnell, einfach und absolut unverbindlich.
Zur optimalen Vorbereitung:
- Ihr Anliegen
- Wunsch-Ergebnis
- Bisherige Schritte
Oder kontaktieren Sie uns direkt:
Zertifikate, Partner und mehr...





Datenstrategie für KI
Unsere Stärken
- Führende Expertise in KI-optimierten Datenstrategien
- Ganzheitliche Data Governance für AI-Transformation
- Strategische C-Level-Beratung für datengetriebene Innovation
- Bewährte Frameworks für skalierbare AI-Datenarchitekturen
⚠
Expertentipp
Eine strategische Datenstrategie für KI geht weit über technische Datenmanagement-Aspekte hinaus. Sie erfordert eine ganzheitliche Betrachtung von Datenqualität, Governance, Architektur und Business Alignment, um das volle Potenzial von AI-Investitionen zu realisieren und nachhaltigen Geschäftswert zu schaffen.
ADVISORI in Zahlen
11+
Jahre Erfahrung
120+
Mitarbeiter
520+
Projekte
Wir entwickeln mit Ihnen eine maßgeschneiderte Datenstrategie, die perfekt auf Ihre KI-Ziele und Geschäftsanforderungen abgestimmt ist und gleichzeitig skalierbare, zukunftssichere Datenarchitekturen schafft.
Unser Vorgehen
1
Phase 1
Umfassende Datenlandschaft-Analyse und AI-Readiness-Assessment
2
Phase 2
Strategische Datenarchitektur-Planung für KI-Optimierung
3
Phase 3
Data Governance-Framework-Implementierung und Quality Management
4
Phase 4
Aufbau skalierbarer Data Pipelines und ML-Infrastrukturen
5
Phase 5
Kontinuierliche Optimierung und strategische Weiterentwicklung
"Eine strategische Datenstrategie ist das Fundament jeder erfolgreichen KI-Initiative. Unser Ansatz verbindet technische Exzellenz mit strategischer Weitsicht, um Daten als wertvollsten Unternehmensasset zu positionieren. Wir schaffen nicht nur Datenarchitekturen, sondern ermöglichen datengetriebene Geschäftstransformation, die nachhaltigen Wettbewerbsvorteile und messbaren Business Value generiert."

Asan Stefanski
Head of Digital Transformation
Expertise & Erfahrung:
11+ Jahre Erfahrung, Studium Angewandte Informatik, Strategische Planung und Leitung von KI-Projekten, Cyber Security, Secure Software Development, AI
Unsere Dienstleistungen
Wir bieten Ihnen maßgeschneiderte Lösungen für Ihre digitale Transformation
Strategic Data Assessment & AI Readiness
Umfassende Bewertung Ihrer Datenlandschaft und Entwicklung einer strategischen Roadmap für KI-optimierte Datenarchitekturen.
- Datenlandschaft-Analyse und AI-Potenzial-Assessment
- Data Maturity Evaluation und Gap-Analyse
- Strategische Datenarchitektur-Roadmap
- ROI-Bewertung und Business Case-Entwicklung
KI-optimierte Datenarchitektur-Design
Entwicklung skalierbarer, zukunftssicherer Datenarchitekturen, die speziell für KI-Anforderungen optimiert sind.
- Modern Data Stack-Architektur für AI/ML
- Cloud-native und Hybrid-Datenplattformen
- Skalierbare Data Lake und Data Warehouse-Konzepte
- Real-time Streaming und Batch-Processing-Architekturen
Unsere Kompetenzen im Bereich KI - Künstliche Intelligenz
Wählen Sie den passenden Bereich für Ihre Anforderungen
AI Governance Beratung
Ihre Mitarbeiter nutzen bereits KI. Im Marketing schreibt ChatGPT Texte mit Kundendaten. Im Vertrieb analysiert Copilot vertrauliche Angebote. In der Buchhaltung prüft eine KI Rechnungen. Die Geschäftsführung? Weiß in den meisten Fällen nichts davon. Kein Überblick, keine Regeln, keine Kontrolle. Das ist der Normalzustand in deutschen Unternehmen — und es ist eine tickende Zeitbombe.
Absicherung von KI-Systemen
Schützen Sie Ihre KI-Systeme mit maßgeschneiderten Sicherheitsmaßnahmen. ADVISORI sichert Ihre AI-Infrastruktur gegen Adversarial Attacks, Data Poisoning und Model Extraction – EU AI Act-konform und DSGVO-ready.
Adversarial KI Attacks
Schützen Sie Ihre KI-Modelle vor Adversarial Attacks mit spezialisierten Abwehrstrategien. ADVISORI analysiert Ihre KI-Systeme auf adversarielle Schwachstellen und implementiert robuste Schutzmaßnahmen – EU AI Act-konform und DSGVO-ready.
Aufbau interner KI-Kompetenzen
Bauen Sie KI-Kompetenzen systematisch auf - von der Fuehrungsebene bis zu operativen Teams. ADVISORI entwickelt Ihre KI-Schulungsstrategie, ein KI Center of Excellence und EU AI Act-konforme Talentprogramme für nachhaltige Wettbewerbsvorteile.
Azure OpenAI Sicherheit
Nutzen Sie die Kraft von Azure OpenAI mit unserem Safety-First-Ansatz. Wir implementieren sichere, DSGVO-konforme Cloud-AI-Lösungen, die Ihr geistiges Eigentum schützen und gleichzeitig die volle Innovationskraft von Microsoft Azure OpenAI erschließen.
Beratung KI-Sicherheit
Schuetzen Sie Ihr Unternehmen vor KI-spezifischen Risiken mit professioneller KI-Sicherheitsberatung. ADVISORI entwickelt EU AI Act-konforme Security Frameworks, schuetzt vor Adversarial Attacks und Data Poisoning und sichert Ihre KI-Systeme DSGVO-konform.
DSGVO für KI
Implementieren Sie Künstliche Intelligenz rechtskonform und datenschutzfreundlich. Unsere Experten unterstützen Sie bei der DSGVO-konformen Gestaltung von AI-Systemen, von der Konzeption bis zur Umsetzung.
DSGVO-konforme KI-Lösungen
Künstliche Intelligenz unter vollständiger DSGVO-Compliance: Privacy-by-Design-Implementierung, automatisierte Entscheidungsfindung nach Art. 22 DSGVO, Datenschutz-Folgenabschätzung (DSFA) für KI-Systeme und Vorbereitung auf den EU AI Act. ADVISORI macht Ihre KI rechtskonform, erklärbar und auditbereit.
Data Poisoning KI
Data Poisoning Angriffe vergiften KI-Modelle durch manipulierte Trainingsdaten – oft unbemerkt bis zum Produktiveinsatz. ADVISORI erkennt und neutralisiert diese Bedrohungen mit forensischer Datenanalyse, Anomalie-Erkennung und Safety-by-Design-Architekturen. Schützen Sie Ihre KI-Investitionen und erfüllen Sie die Sicherheitsanforderungen des EU AI Act.
Datenintegration für KI
Ohne hochwertige, integrierte Daten kein leistungsstarkes KI-Modell. ADVISORI entwickelt DSGVO-konforme Datenpipelines und Enterprise Data Architectures, die Ihre Rohdaten in auditierbare, KI-gerechte Datensaetze verwandeln. Von der Datenquelle bis zum trainierten Modell - sicher, skalierbar und compliant.
Datenlecks durch LLMs verhindern
Schützen Sie Ihr Unternehmen vor Datenlecks durch Large Language Models. Unsere Safety-First-Methodik gewährleistet DSGVO-konforme LLM-Implementierungen mit umfassendem Schutz Ihres geistigen Eigentums und sensibler Unternehmensdaten.
Datenschutz bei KI
KI-Systeme verarbeiten personenbezogene Daten in nie dagewesenem Umfang. ADVISORI implementiert Datenschutz by Design für Ihre KI-Projekte: DSGVO-konforme Datenarchitekturen, risikobasierte Datenschutz-Folgenabschaetzungen und EU AI Act-Compliance. Nutzen Sie das Potenzial von KI ohne rechtliche Risiken.
Datenschutz für KI
Setzen Sie Künstliche Intelligenz rechtssicher ein. Unsere KI-Datenschutzexperten implementieren Privacy-by-Design-Architekturen, sichern personenbezogene Daten in AI-Systemen und begleiten Sie durch alle DSGVO-Anforderungen und EU AI Act Pflichten – ohne Kompromisse bei der KI-Performance.
Datensicherheit für KI
Schützen Sie KI-Trainingsdaten, Modelle und Inferenz-Pipelines vor Angriffen und Datenverlust. Unsere Datensicherheitsexperten implementieren technische Schutzmaßnahmen für den gesamten ML-Lebenszyklus — von der Datensammlung über das Training bis zum produktiven Einsatz Ihrer KI-Systeme.
Deployment von KI-Modellen
Bringen Sie Ihre KI-Modelle zuverlässig und skalierbar in die Produktion. Unsere MLOps-Experten implementieren robuste Deployment-Pipelines, automatisieren CI/CD-Prozesse für KI-Modelle und gewährleisten kontinuierliches Monitoring — damit Ihre KI-Systeme performant, DSGVO-konform und EU AI Act-compliant betrieben werden.
EU AI Act Compliance
Seit Februar 2025 gelten die ersten Verbote des EU AI Acts. Stellen Sie sich vor: Montagmorgen, Ihr wichtigster Kunde meldet sich – seine Bank hat gerade eine Warnung der Aufsichtsbehörde erhalten. Grund: Das KI-System für Kreditentscheidungen erfüllt nicht die EU AI Act Anforderungen. Potenzielle Strafe: 35 Millionen Euro oder 7% des Jahresumsatzes. Was als Effizienz-Tool gedacht war, wird zur existenziellen Bedrohung.
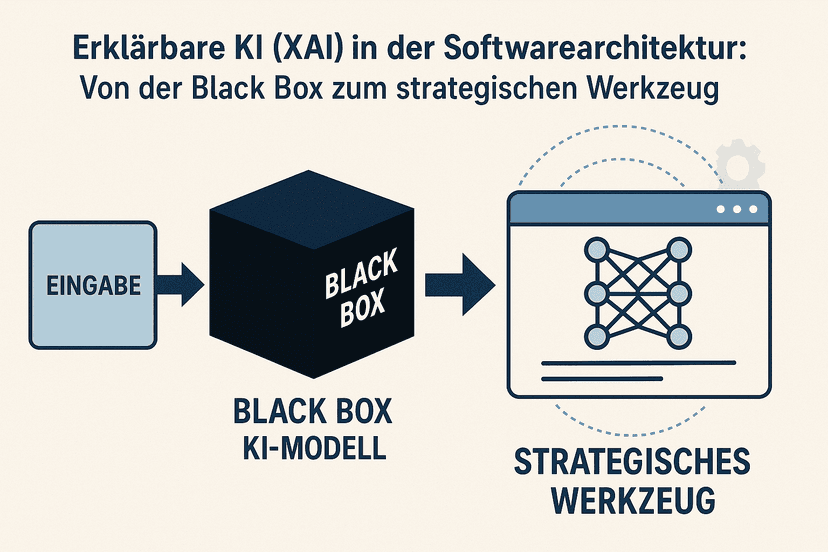
Erklärbare KI
Schaffen Sie Vertrauen und Compliance mit transparenten KI-Systemen. Unsere Explainable AI (XAI) Lösungen machen komplexe Algorithmen nachvollziehbar und ermöglichen fundierte Geschäftsentscheidungen bei gleichzeitiger Erfüllung regulatorischer Anforderungen.
Explainable AI (XAI)
KI-Entscheidungen müssen erkläbar, nachvollziehbar und auditierbar sein – gefordert von DSGVO Art. 22 und EU AI Act. ADVISORI implementiert Explainable-AI-Methoden (SHAP, LIME, Counterfactual Explanations), die Vertrauen schaffen, regulatorische Transparenzpflichten erfüllen und Ihr KI-System audit-ready machen.
Gefahren durch KI
KI birgt erhebliche Gefahren: von Adversarial Attacks und Data Poisoning über KI-Halluzinationen bis zu Datenschutzverstößen und EU AI Act-Risiken. ADVISORI identifiziert, bewertet und minimiert KI-Gefahren mit einem Safety-First-Ansatz – für regulatorisch sichere und verantwortungsvolle KI-Implementierung.
KI Computer Vision
Computer Vision ist eine der am schnellsten wachsenden KI-Anwendungen. Wir entwickeln und implementieren DSGVO- und AI-Act-konforme Computer Vision Loesungen für Unternehmen.
Häufig gestellte Fragen zur Datenstrategie für KI
Wie entwickelt ADVISORI eine strategische Datenstrategie für KI und welche fundamentalen Prinzipien bestimmen den Erfolg von AI-driven Data Governance?
Eine strategische Datenstrategie für KI ist weit mehr als technisches Datenmanagement – sie ist der strategische Grundstein für nachhaltige AI-Transformation und Wettbewerbsvorteile. ADVISORI entwickelt ganzheitliche Datenstrategien, die Daten als wertvollsten Unternehmensasset positionieren und gleichzeitig die spezifischen Anforderungen von KI-Systemen erfüllen. Unser Ansatz verbindet strategische Weitsicht mit operativer Exzellenz für maximalen Business Value.
🎯 Strategische Grundprinzipien für KI-Datenstrategien:
•
Data as a Strategic Asset: Positionierung von Daten als zentraler Wertschöpfungstreiber und Grundlage für datengetriebene Geschäftsmodelle und Innovationen.
•
AI-First Architecture: Entwicklung von Datenarchitekturen, die von Grund auf für KI-Anforderungen optimiert sind und Machine Learning-Workloads nativ unterstützen.
•
Business Alignment: Enge Verzahnung der Datenstrategie mit Geschäftszielen und strategischen Initiativen für maximale Wertschöpfung.
•
Scalability by Design: Aufbau skalierbarer Dateninfrastrukturen, die mit wachsenden AI-Anforderungen und Datenvolumen mitwachsen können.
•
Quality-First Approach: Implementierung rigoroser Datenqualitäts-Standards als Fundament für vertrauenswürdige und leistungsstarke KI-Systeme.
🏗 ️ ADVISORI's strategischer Entwicklungsansatz:
•
Comprehensive Data Assessment: Umfassende Analyse der bestehenden Datenlandschaft, Identifikation von Stärken, Schwächen und strategischen Potenzialen.
Welche kritischen Faktoren bestimmen die Datenqualität für Machine Learning und wie implementiert ADVISORI ML-Ready Data Preparation Frameworks?
Datenqualität ist der entscheidende Erfolgsfaktor für Machine Learning-Projekte – selbst die fortschrittlichsten Algorithmen können nur so gut sein wie die Daten, mit denen sie trainiert werden. ADVISORI hat spezialisierte ML-Ready Data Preparation Frameworks entwickelt, die sicherstellen, dass Ihre Daten die höchsten Qualitätsstandards für KI-Anwendungen erfüllen. Unser systematischer Ansatz transformiert rohe Datenbestände in hochwertige, ML-optimierte Assets.
🔍 Kritische Datenqualitätsdimensionen für ML:
•
Accuracy und Correctness: Sicherstellung der faktischen Richtigkeit und Präzision von Daten durch umfassende Validierungs- und Verifizierungsprozesse.
•
Completeness und Coverage: Gewährleistung vollständiger Datensätze ohne kritische Lücken, die ML-Modelle beeinträchtigen könnten.
•
Consistency und Standardization: Harmonisierung von Datenformaten, Einheiten und Strukturen für einheitliche ML-Verarbeitung.
•
Timeliness und Freshness: Sicherstellung aktueller und zeitnaher Daten für relevante und aussagekräftige ML-Ergebnisse.
•
Relevance und Feature Quality: Identifikation und Aufbereitung der für ML-Ziele relevantesten Datenattribute und Features.
🛠 ️ ADVISORI's ML-Ready Data Preparation Framework:
•
Automated Data Profiling: Einsatz fortschrittlicher Tools zur automatischen Analyse und Bewertung von Datenqualität, Verteilungen und Anomalien.
Wie gestaltet ADVISORI moderne Data Architectures für KI und welche Technologien ermöglichen skalierbare AI-Infrastrukturen?
Moderne Data Architectures für KI erfordern einen fundamentalen Paradigmenwechsel von traditionellen Datenarchitekturen hin zu AI-nativen, cloud-optimierten und hochskalierbaren Infrastrukturen. ADVISORI entwickelt cutting-edge Datenarchitekturen, die speziell für die Anforderungen von Machine Learning, Real-time Analytics und Large-Scale AI-Workloads konzipiert sind. Unser Ansatz kombiniert bewährte Architekturprinzipien mit innovativen Technologien für maximale Performance und Flexibilität.
🏗 ️ Fundamentale Architekturprinzipien für AI-Infrastrukturen:
•
Cloud-Native Design: Entwicklung von Architekturen, die die nativen Capabilities von Cloud-Plattformen optimal nutzen und Multi-Cloud-Strategien unterstützen.
•
Microservices und API-First: Modulare, service-orientierte Architekturen, die Flexibilität, Skalierbarkeit und einfache Integration ermöglichen.
•
Event-Driven Architecture: Implementierung ereignisgesteuerter Systeme für Real-time Data Processing und responsive AI-Anwendungen.
•
Containerization und Orchestration: Nutzung von Container-Technologien für portable, skalierbare und effiziente AI-Workload-Deployment.
•
Infrastructure as Code: Automatisierte, versionskontrollierte Infrastruktur-Bereitstellung für Konsistenz und Reproduzierbarkeit.
🚀 Modern Data Stack für AI/ML:
•
Data Lake und Lakehouse Architectures: Implementierung flexibler, schema-on-read Datenarchitekturen, die strukturierte und unstrukturierte Daten für AI-Anwendungen optimieren.
Welche Strategien verfolgt ADVISORI für Data Monetization durch KI und wie werden Daten zu messbaren Geschäftswerten transformiert?
Data Monetization durch KI repräsentiert eine der wertvollsten Möglichkeiten für Unternehmen, ihre Dateninvestitionen in messbare Geschäftswerte zu transformieren. ADVISORI entwickelt strategische Monetarisierungsansätze, die Daten von Kostenfaktoren zu Profit-Centern wandeln und neue Umsatzströme erschließen. Unser systematischer Ansatz identifiziert, entwickelt und skaliert datengetriebene Geschäftsmodelle für nachhaltigen Wettbewerbsvorteile.
💰 Strategische Data Monetization Frameworks:
•
Direct Revenue Generation: Entwicklung von datenbasierten Produkten und Services, die direkte Umsätze generieren, wie Data-as-a-Service-Angebote oder AI-powered Analytics-Lösungen.
•
Operational Efficiency Optimization: Nutzung von KI und Datenanalysen zur Optimierung interner Prozesse, Kostensenkung und Produktivitätssteigerung.
•
Customer Experience Enhancement: Implementierung datengetriebener Personalisierung und Kundenservice-Verbesserungen für höhere Customer Lifetime Values.
•
Risk Mitigation und Compliance: Einsatz von AI-gestützten Risikomanagement-Systemen zur Reduzierung von Verlusten und Compliance-Kosten.
•
Innovation und New Business Models: Entwicklung völlig neuer, datengetriebener Geschäftsmodelle und Marktchancen.
🎯 ADVISORI's Value Creation Methodology:
•
Data Asset Valuation: Systematische Bewertung und Quantifizierung des Wertes vorhandener Datenbestände und deren Monetarisierungspotenzial.
•
Use Case Identification: Identifikation und Priorisierung der wertvollsten AI-Anwendungsfälle basierend auf ROI-Potenzialen und strategischer Relevanz.
Wie implementiert ADVISORI Real-time Data Pipelines für kontinuierliches Machine Learning und welche Technologien ermöglichen Stream Processing für AI?
Real-time Data Pipelines sind das Rückgrat moderner AI-Systeme, die kontinuierliches Lernen und sofortige Reaktionen auf sich ändernde Datenlandschaften ermöglichen. ADVISORI entwickelt hochperformante Stream Processing-Architekturen, die massive Datenströme in Echtzeit verarbeiten und ML-Modelle kontinuierlich mit frischen Daten versorgen. Unser Ansatz kombiniert cutting-edge Technologien mit bewährten Architekturprinzipien für maximale Zuverlässigkeit und Performance.
🚀 Fundamentale Real-time Data Pipeline Architektur:
•
Event-Driven Architecture: Implementierung ereignisgesteuerter Systeme, die auf Datenänderungen in Echtzeit reagieren und ML-Workflows automatisch auslösen.
•
Microservices-basierte Processing: Modulare, unabhängig skalierbare Services für verschiedene Aspekte der Datenverarbeitung und ML-Pipeline-Orchestrierung.
•
Fault-Tolerant Design: Aufbau robuster Systeme mit automatischer Fehlerbehandlung, Retry-Mechanismen und Graceful Degradation.
•
Horizontal Scalability: Architekturen, die automatisch mit steigenden Datenvolumen und Processing-Anforderungen skalieren können.
•
Low-Latency Processing: Optimierung für minimale Verarbeitungszeiten von Millisekunden bis Sekunden für zeitkritische AI-Anwendungen.
🔧 Advanced Stream Processing Technologies:
•
Apache Kafka Ecosystem: Nutzung von Kafka Streams, Kafka Connect und KSQL für robuste, skalierbare Event Streaming und Real-time Analytics.
Welche Rolle spielt Master Data Management bei KI-Implementierungen und wie gewährleistet ADVISORI konsistente, hochwertige Stammdaten für AI-Systeme?
Master Data Management ist das Fundament für vertrauenswürdige und konsistente KI-Systeme, da es die einheitliche, autoritative Sicht auf kritische Geschäftsentitäten gewährleistet. ADVISORI entwickelt fortschrittliche MDM-Strategien, die speziell für KI-Anforderungen optimiert sind und sicherstellen, dass AI-Systeme auf konsistenten, hochwertigen Stammdaten basieren. Unser Ansatz schafft die Datengrundlage für präzise, vertrauenswürdige und skalierbare KI-Anwendungen.
🎯 Strategische Bedeutung von MDM für KI:
•
Single Source of Truth: Etablierung einer einheitlichen, autoritativen Datenquelle für kritische Geschäftsentitäten wie Kunden, Produkte, Lieferanten und Standorte.
•
Data Consistency Across Systems: Gewährleistung konsistenter Datenrepräsentation über alle Systeme und Anwendungen hinweg für einheitliche KI-Ergebnisse.
•
Enhanced Data Quality: Systematische Verbesserung der Datenqualität durch Deduplizierung, Standardisierung und Anreicherung von Stammdaten.
•
Improved AI Accuracy: Bereitstellung hochwertiger, konsistenter Trainingsdaten für präzisere und zuverlässigere ML-Modelle.
•
Regulatory Compliance: Unterstützung von Compliance-Anforderungen durch einheitliche Datengovernance und Audit-Trails.
🏗 ️ ADVISORI's AI-optimierte MDM-Architektur:
•
Hybrid MDM Approach: Kombination von zentralisierten und föderierten MDM-Ansätzen für optimale Balance zwischen Kontrolle und Flexibilität.
Wie entwickelt ADVISORI Cross-funktionale Datenintegrations-Strategien für AI und welche Herausforderungen entstehen bei der Harmonisierung heterogener Datenquellen?
Cross-funktionale Datenintegration für AI erfordert die nahtlose Verbindung heterogener Datenquellen aus verschiedenen Geschäftsbereichen zu einem kohärenten, AI-ready Datenökosystem. ADVISORI entwickelt sophisticated Integrationsstrategien, die technische, organisatorische und governance-bezogene Herausforderungen adressieren und eine einheitliche Datenbasis für unternehmensweite KI-Initiativen schaffen. Unser Ansatz überbrückt Silos und schafft synergetische Datenlandschaften.
🔗 Fundamentale Integrations-Herausforderungen:
•
Data Silos und Legacy Systems: Überwindung isolierter Datenbestände in verschiedenen Abteilungen und Integration veralteter Systeme mit modernen AI-Plattformen.
•
Schema und Format Heterogenität: Harmonisierung unterschiedlicher Datenstrukturen, Formate und Semantiken aus diversen Quellsystemen.
•
Data Quality Inconsistencies: Bewältigung unterschiedlicher Datenqualitätsstandards und Konsistenzlevel zwischen verschiedenen Datenquellen.
•
Organizational Boundaries: Navigation komplexer organisatorischer Strukturen und Verantwortlichkeiten für erfolgreiche Datenintegration.
•
Real-time vs. Batch Processing: Balancierung verschiedener Verarbeitungsanforderungen und Latenz-Erwartungen unterschiedlicher Geschäftsbereiche.
🏗 ️ ADVISORI's Integrations-Framework:
•
API-First Integration Strategy: Entwicklung einheitlicher API-Schichten für standardisierte Datenintegration und Service-orientierte Architekturen.
•
Event-Driven Data Mesh: Implementierung dezentraler, domain-orientierter Datenarchitekturen mit event-getriebener Kommunikation zwischen Domänen.
•
Semantic Data Layer: Aufbau semantischer Abstraktionsschichten, die unterschiedliche Datenmodelle und -strukturen harmonisieren.
Welche innovativen Ansätze verfolgt ADVISORI für Data Lifecycle Management in KI-Projekten und wie wird die Evolution von Daten über Zeit optimiert?
Data Lifecycle Management für KI-Projekte erfordert einen strategischen Ansatz zur Verwaltung von Daten von ihrer Entstehung bis zur Archivierung, wobei die sich ändernden Anforderungen von ML-Modellen und Geschäftsprozessen berücksichtigt werden. ADVISORI entwickelt innovative Lifecycle-Management-Strategien, die Datenqualität, Verfügbarkeit und Compliance über den gesamten Lebenszyklus optimieren und gleichzeitig Kosten und Komplexität minimieren.
🔄 Strategische Lifecycle-Phasen für AI-Daten:
•
Data Creation und Acquisition: Optimierte Prozesse für die Erfassung und Generierung hochwertiger Daten mit AI-Readiness von Beginn an.
•
Data Processing und Enrichment: Intelligente Verarbeitung und Anreicherung von Rohdaten für maximale ML-Tauglichkeit und Business Value.
•
Data Storage und Management: Strategische Speicherung mit optimierten Zugriffspfaden für verschiedene AI-Workloads und Anwendungsszenarien.
•
Data Usage und Analytics: Maximierung der Datennutzung durch intelligente Discovery, Sharing und Collaboration-Mechanismen.
•
Data Archival und Retention: Kostenoptimierte Langzeitspeicherung mit Compliance-konformer Aufbewahrung und Löschung.
🚀 ADVISORI's Lifecycle Optimization Framework:
•
Intelligent Data Tiering: Automatische Klassifizierung und Tiering von Daten basierend auf Nutzungsmustern, Geschäftswert und Zugriffshäufigkeit.
Wie entwickelt ADVISORI Data Mesh Architekturen für dezentrale KI-Datenstrategien und welche Governance-Modelle ermöglichen skalierbare Domain-orientierte Datenorganisation?
Data Mesh Architekturen revolutionieren traditionelle zentralisierte Datenansätze durch dezentrale, domain-orientierte Datenorganisation, die besonders für große, komplexe Organisationen mit vielfältigen KI-Anforderungen geeignet ist. ADVISORI implementiert Data Mesh-Strategien, die lokale Autonomie mit globaler Konsistenz verbinden und skalierbare, selbstorganisierende Datenökosysteme schaffen.
🌐 Data Mesh Grundprinzipien für KI:
•
Domain-oriented Decentralized Data Ownership: Verteilung der Datenverantwortung an fachliche Domänen für bessere Datenqualität und Business Alignment.
•
Data as a Product: Behandlung von Daten als Produkte mit klaren SLAs, Qualitätsstandards und Kundenorientierung.
•
Self-serve Data Infrastructure: Bereitstellung von Self-Service-Plattformen für autonome Datennutzung und KI-Entwicklung.
•
Federated Computational Governance: Dezentrale Governance-Modelle mit globalen Standards und lokaler Flexibilität.
🏗 ️ ADVISORI's Data Mesh Implementation:
•
Domain Data Teams: Aufbau spezialisierter Teams für verschiedene Datendomänen mit KI-Expertise und Geschäftsverständnis.
•
Data Product Platforms: Entwicklung von Plattformen für die Bereitstellung und Nutzung von Datenprodukten als Services.
•
Interoperability Standards: Etablierung von Standards für die Interoperabilität zwischen verschiedenen Datendomänen.
•
Governance Automation: Automatisierung von Governance-Prozessen für konsistente Qualität und Compliance.
Welche Strategien verfolgt ADVISORI für Cloud-native Data Strategies und wie werden Multi-Cloud-Umgebungen für KI-Workloads optimiert?
Cloud-native Data Strategies sind essentiell für moderne KI-Implementierungen, da sie Skalierbarkeit, Flexibilität und Kosteneffizienz ermöglichen. ADVISORI entwickelt Multi-Cloud-Strategien, die die besten Services verschiedener Cloud-Anbieter kombinieren und gleichzeitig Vendor Lock-in vermeiden. Unser Ansatz optimiert Cloud-Ressourcen für verschiedene KI-Workloads und Geschäftsanforderungen.
☁ ️ Cloud-Native Architekturprinzipien:
•
Microservices-basierte Datenservices: Modulare, unabhängig skalierbare Services für verschiedene Datenverarbeitungsaufgaben.
•
Containerization: Nutzung von Containern für portable, konsistente Deployment-Umgebungen.
•
Auto-Scaling: Automatische Skalierung basierend auf Workload-Anforderungen und Kostenoptimierung.
•
Serverless Computing: Event-getriebene, serverlose Funktionen für kosteneffiziente Datenverarbeitung.
🌐 Multi-Cloud Strategy Framework:
•
Best-of-Breed Service Selection: Auswahl der besten Services von verschiedenen Cloud-Anbietern für spezifische Anwendungsfälle.
•
Data Portability: Sicherstellung der Portabilität von Daten und Anwendungen zwischen verschiedenen Cloud-Umgebungen.
•
Unified Management: Einheitliche Management-Plattformen für Multi-Cloud-Umgebungen.
•
Cost Optimization: Kontinuierliche Optimierung der Cloud-Kosten durch intelligente Ressourcenallokation.
🔧 Cloud-Native Data Technologies:
•
Managed Data Services: Nutzung von managed Services für Datenbanken, Analytics und ML-Plattformen.
•
Data Lakes und Warehouses: Cloud-native Implementierung von Data Lakes und Data Warehouses.
Wie implementiert ADVISORI Feature Stores für konsistente ML-Feature-Verwaltung und welche Technologien ermöglichen Enterprise-weite Feature-Wiederverwendung?
Feature Stores sind zentrale Komponenten moderner ML-Infrastrukturen, die konsistente, wiederverwendbare Features für verschiedene ML-Modelle und Teams bereitstellen. ADVISORI entwickelt Enterprise-Feature-Store-Architekturen, die Feature-Engineering-Effizienz maximieren, Konsistenz gewährleisten und die Zusammenarbeit zwischen ML-Teams fördern.
🎯 Feature Store Kernfunktionalitäten:
•
Centralized Feature Repository: Zentrale Verwaltung aller ML-Features mit Versionskontrolle und Metadaten.
•
Real-time und Batch Serving: Bereitstellung von Features für sowohl Training als auch Inference-Szenarien.
•
Feature Discovery: Suchbare Feature-Kataloge für bessere Wiederverwendung und Collaboration.
•
Data Lineage: Vollständige Nachverfolgung der Feature-Herkunft und Transformationen.
🏗 ️ ADVISORI's Feature Store Architecture:
•
Offline Feature Store: Batch-Processing für Training-Features mit historischen Daten.
•
Online Feature Store: Low-Latency Feature Serving für Real-time Inference.
•
Feature Pipeline Orchestration: Automatisierte Pipelines für Feature-Generierung und -Updates.
•
Quality Monitoring: Kontinuierliche Überwachung der Feature-Qualität und -Drift.
🔧 Technology Stack:
•
Storage Technologies: Optimierte Speicherlösungen für verschiedene Feature-Typen und Zugriffsmuster.
•
Compute Engines: Skalierbare Compute-Plattformen für Feature-Engineering und -Transformation.
•
API Layers: Standardisierte APIs für Feature-Zugriff und -Management.
•
Integration Tools: Nahtlose Integration mit bestehenden ML-Pipelines und -Tools.
Welche Rolle spielt Data Observability bei KI-Datenstrategien und wie gewährleistet ADVISORI kontinuierliche Überwachung der Datenqualität und -performance?
Data Observability ist kritisch für vertrauenswürdige KI-Systeme, da sie kontinuierliche Einblicke in Datenqualität, -performance und -verhalten ermöglicht. ADVISORI implementiert umfassende Observability-Frameworks, die proaktive Problemerkennung, automatische Alerting und kontinuierliche Optimierung von Datenlandschaften ermöglichen.
🔍 Data Observability Dimensionen:
•
Data Quality Monitoring: Kontinuierliche Überwachung von Datenqualitäts-Metriken wie Vollständigkeit, Genauigkeit und Konsistenz.
•
Data Freshness: Monitoring der Aktualität und Zeitnähe von Daten für zeitkritische KI-Anwendungen.
•
Data Volume: Überwachung von Datenvolumen und -wachstum für Kapazitätsplanung.
•
Schema Evolution: Tracking von Schema-Änderungen und deren Auswirkungen auf nachgelagerte Systeme.
🚨 Proactive Monitoring und Alerting:
•
Anomaly Detection: ML-basierte Erkennung von Datenanomalien und ungewöhnlichen Mustern.
•
Threshold-based Alerts: Konfigurierbare Schwellenwerte für verschiedene Datenqualitäts-Metriken.
•
Impact Analysis: Automatische Analyse der Auswirkungen von Datenproblemen auf nachgelagerte Systeme.
•
Root Cause Analysis: Intelligente Identifikation der Grundursachen von Datenproblemen.
🛠 ️ Observability Technology Stack:
•
Monitoring Platforms: Spezialisierte Plattformen für Data Observability und Monitoring.
•
Visualization Tools: Dashboards und Visualisierungen für Datenqualitäts-Metriken.
•
Integration APIs: APIs für die Integration mit bestehenden Monitoring- und Alerting-Systemen.
Wie entwickelt ADVISORI DataOps-Strategien für agile KI-Datenentwicklung und welche Automatisierungsansätze optimieren Data Pipeline Management?
DataOps revolutioniert traditionelle Datenmanagement-Ansätze durch die Anwendung agiler und DevOps-Prinzipien auf Datenpipelines und Analytics-Workflows. ADVISORI implementiert DataOps-Strategien, die Entwicklungszyklen beschleunigen, Datenqualität verbessern und die Zusammenarbeit zwischen Data Teams optimieren. Unser Ansatz schafft selbstheilende, automatisierte Dateninfrastrukturen für kontinuierliche KI-Innovation.
🔄 DataOps Kernprinzipien für KI:
•
Continuous Integration/Continuous Deployment: Automatisierte CI/CD-Pipelines für Datenworkflows und ML-Modelle.
•
Version Control für Data Assets: Umfassende Versionskontrolle für Datensätze, Schemas und Transformationslogik.
•
Automated Testing: Systematische Tests für Datenqualität, Pipeline-Performance und Modell-Validierung.
•
Monitoring und Observability: Kontinuierliche Überwachung aller Datenoperationen mit proaktivem Alerting.
🚀 ADVISORI's DataOps Implementation:
•
Infrastructure as Code: Vollständig automatisierte Infrastruktur-Bereitstellung für reproduzierbare Datenumgebungen.
•
Pipeline Orchestration: Intelligente Orchestrierung komplexer Datenworkflows mit Dependency Management.
•
Self-Service Analytics: Demokratisierung von Datenanalysen durch Self-Service-Plattformen für Fachbereiche.
•
Collaborative Development: Förderung der Zusammenarbeit zwischen Data Engineers, Scientists und Analysts.
🛠 ️ Automation Technologies:
•
Workflow Orchestration Tools: Apache Airflow, Prefect und andere Tools für komplexe Pipeline-Orchestrierung.
•
Data Quality Automation: Automatisierte Datenqualitätsprüfungen und -korrekturen in allen Pipeline-Stufen.
Welche Ansätze verfolgt ADVISORI für Regulatory Data Management in KI-Kontexten und wie werden Compliance-Anforderungen in Datenstrategien integriert?
Regulatory Data Management für KI erfordert die nahtlose Integration von Compliance-Anforderungen in alle Aspekte der Datenstrategie. ADVISORI entwickelt Compliance-by-Design-Ansätze, die regulatorische Anforderungen von Beginn an in Datenarchitekturen einbetten und gleichzeitig Flexibilität für KI-Innovation bewahren. Unser Framework gewährleistet kontinuierliche Compliance bei maximaler Datennutzung.
📋 Regulatory Compliance Framework:
•
DSGVO und Privacy Regulations: Umfassende Integration von Datenschutzanforderungen in KI-Datenstrategien.
•
Industry-Specific Regulations: Branchenspezifische Compliance für Finanzdienstleistungen, Healthcare, Automotive und andere regulierte Industrien.
•
Cross-Border Data Governance: Management internationaler Datentransfers und lokaler Compliance-Anforderungen.
•
Audit Readiness: Kontinuierliche Audit-Bereitschaft durch umfassende Dokumentation und Nachverfolgbarkeit.
🔒 Privacy-Preserving Data Strategies:
•
Data Minimization: Implementierung von Datenminimierungsstrategien für Compliance-konforme KI-Entwicklung.
•
Pseudonymization und Anonymization: Fortschrittliche Techniken für die Anonymisierung von Trainingsdaten.
•
Consent Management: Dynamische Einwilligungsverwaltung für personenbezogene Daten in KI-Systemen.
•
Right to be Forgotten: Technische Implementierung des Rechts auf Vergessenwerden in ML-Modellen.
🛡 ️ Technical Compliance Implementation:
•
Automated Compliance Monitoring: Kontinuierliche Überwachung der Compliance-Konformität in Echtzeit.
•
Policy Enforcement: Automatische Durchsetzung von Compliance-Richtlinien in Datenverarbeitungspipelines.
Wie implementiert ADVISORI Edge Computing Data Strategies für dezentrale KI-Verarbeitung und welche Herausforderungen entstehen bei der Datenverteilung?
Edge Computing Data Strategies ermöglichen KI-Verarbeitung näher an der Datenquelle und reduzieren Latenz, Bandbreitenverbrauch und Datenschutzrisiken. ADVISORI entwickelt dezentrale Datenarchitekturen, die die Vorteile von Edge Computing maximieren und gleichzeitig zentrale Governance und Qualitätsstandards aufrechterhalten. Unser Ansatz schafft hybride Edge-Cloud-Ökosysteme für optimale KI-Performance.
🌐 Edge Computing Architekturprinzipien:
•
Distributed Data Processing: Verteilung von Datenverarbeitung auf Edge-Devices für reduzierte Latenz.
•
Local Data Storage: Strategische Datenspeicherung am Edge für autonome Verarbeitung und Compliance.
•
Hierarchical Data Management: Mehrstufige Datenarchitekturen von Edge über Fog bis zur Cloud.
•
Intelligent Data Synchronization: Selektive Synchronisation kritischer Daten zwischen Edge und zentralen Systemen.
🔧 Technical Implementation Strategies:
•
Edge AI Frameworks: Optimierte ML-Frameworks für ressourcenbeschränkte Edge-Umgebungen.
•
Data Compression und Optimization: Intelligente Komprimierung für effiziente Datenübertragung.
•
Offline Capability: Robuste Offline-Verarbeitungsfähigkeiten für autonome Edge-Operationen.
•
Security at the Edge: Umfassende Sicherheitsmaßnahmen für dezentrale Datenverarbeitung.
📊 Data Distribution Challenges:
•
Consistency Management: Gewährleistung der Datenkonsistenz über verteilte Edge-Umgebungen.
•
Bandwidth Optimization: Intelligente Nutzung begrenzter Netzwerkressourcen für Datenübertragung.
Welche zukunftsweisenden Trends identifiziert ADVISORI für KI-Datenstrategien und wie bereiten sich Unternehmen auf die nächste Generation von Data Technologies vor?
Die Zukunft der KI-Datenstrategien wird von revolutionären Technologien und sich wandelnden Geschäftsanforderungen geprägt. ADVISORI identifiziert emerging Trends und entwickelt zukunftssichere Strategien, die Unternehmen auf die nächste Generation von Data Technologies vorbereiten. Unser Forward-Looking-Ansatz antizipiert technologische Entwicklungen und schafft adaptive Datenarchitekturen.
🔮 Emerging Technology Trends:
•
Quantum Computing Integration: Vorbereitung auf Quantum-enhanced Data Processing und Cryptography.
•
Neuromorphic Computing: Entwicklung von Datenstrategien für brain-inspired Computing-Architekturen.
•
Autonomous Data Management: Selbstverwaltende Datensysteme mit minimaler menschlicher Intervention.
•
Augmented Analytics: KI-gestützte Analytics-Plattformen für automatisierte Insight-Generierung.
🧠 Next-Generation AI Data Paradigms:
•
Continuous Learning Systems: Datenarchitekturen für kontinuierlich lernende KI-Systeme.
•
Federated AI Ecosystems: Dezentrale KI-Netzwerke mit geteiltem Lernen ohne Datenaustausch.
•
Synthetic Data Generation: Fortschrittliche synthetische Datengenerierung für Privacy-preserving AI.
•
Multimodal Data Integration: Nahtlose Integration verschiedener Datentypen für holistische KI-Modelle.
🚀 Strategic Future Preparation:
•
Technology Roadmapping: Langfristige Technologie-Roadmaps für KI-Datenstrategien.
•
Adaptive Architecture Design: Flexible Architekturen, die sich an neue Technologien anpassen können.
•
Skill Development: Aufbau von Kompetenzen für emerging Data Technologies.
Wie entwickelt ADVISORI Sustainable Data Strategies für umweltbewusste KI-Implementierungen und welche Green Computing-Ansätze optimieren den ökologischen Fußabdruck?
Sustainable Data Strategies werden zunehmend kritisch für verantwortungsvolle KI-Implementierungen, da der Energieverbrauch von Datenverarbeitung und ML-Training erhebliche Umweltauswirkungen hat. ADVISORI entwickelt Green Computing-Strategien, die ökologische Nachhaltigkeit mit technischer Exzellenz verbinden und Unternehmen dabei unterstützen, ihre Klimaziele zu erreichen, ohne KI-Innovation zu kompromittieren.
🌱 Green Data Strategy Prinzipien:
•
Energy-Efficient Architectures: Entwicklung energieoptimierter Datenarchitekturen mit minimaler Umweltbelastung.
•
Carbon-Aware Computing: Intelligente Workload-Planung basierend auf verfügbarer erneuerbarer Energie.
•
Resource Optimization: Maximierung der Ressourceneffizienz durch intelligente Kapazitätsplanung und -nutzung.
•
Lifecycle Assessment: Umfassende Bewertung der Umweltauswirkungen über den gesamten Daten-Lebenszyklus.
♻ ️ Sustainable Technology Implementation:
•
Green Cloud Strategies: Auswahl umweltfreundlicher Cloud-Anbieter mit erneuerbaren Energiequellen.
•
Efficient Data Storage: Optimierung von Speicherstrategien für reduzierten Energieverbrauch.
•
Model Optimization: Entwicklung effizienter ML-Modelle mit reduziertem Trainings- und Inference-Aufwand.
•
Edge Computing Integration: Nutzung von Edge Computing zur Reduzierung von Datenübertragung und Energieverbrauch.
📊 Environmental Impact Monitoring:
•
Carbon Footprint Tracking: Kontinuierliche Messung und Berichterstattung des CO2-Fußabdrucks von Datenoperationen.
•
Energy Consumption Analytics: Detaillierte Analyse des Energieverbrauchs verschiedener Datenworkloads.
Welche Strategien verfolgt ADVISORI für Data Democratization in KI-Organisationen und wie werden Self-Service-Analytics-Plattformen für Citizen Data Scientists implementiert?
Data Democratization ermöglicht es Fachexperten ohne tiefe technische Kenntnisse, eigenständig Datenanalysen durchzuführen und KI-Insights zu generieren. ADVISORI entwickelt Self-Service-Analytics-Plattformen, die komplexe Datenoperationen vereinfachen und gleichzeitig Governance und Qualitätsstandards aufrechterhalten. Unser Ansatz schafft eine datengetriebene Kultur in der gesamten Organisation.
🎯 Data Democratization Framework:
•
Self-Service Data Access: Intuitive Plattformen für einfachen Datenzugriff ohne IT-Abhängigkeiten.
•
No-Code/Low-Code Analytics: Benutzerfreundliche Tools für Datenanalyse ohne Programmierkenntnisse.
•
Automated Data Preparation: Intelligente Datenaufbereitung mit minimaler manueller Intervention.
•
Guided Analytics: Assistierte Analyseprozesse mit Best-Practice-Empfehlungen.
🛠 ️ Citizen Data Scientist Enablement:
•
Training und Enablement: Umfassende Schulungsprogramme für Fachbereichsmitarbeiter.
•
Template Libraries: Vorgefertigte Analyse-Templates für häufige Anwendungsfälle.
•
Collaboration Tools: Plattformen für die Zusammenarbeit zwischen Citizen Data Scientists und IT-Teams.
•
Quality Assurance: Automatische Qualitätsprüfungen für Self-Service-Analysen.
📊 Governance für Self-Service Analytics:
•
Data Catalog Integration: Zentrale Datenkataloge für einfache Datenentdeckung und -verständnis.
•
Access Control: Granulare Zugriffskontrolle für verschiedene Datenebenen und Benutzergruppen.
•
Audit und Compliance: Vollständige Nachverfolgung aller Self-Service-Aktivitäten.
•
Performance Monitoring: Überwachung der Nutzung und Performance von Self-Service-Plattformen.
Wie implementiert ADVISORI Quantum-Ready Data Architectures für zukünftige Quantum Computing-Integration und welche Vorbereitungen sind für Post-Quantum-Datenverarbeitung erforderlich?
Quantum-Ready Data Architectures bereiten Unternehmen auf die revolutionären Möglichkeiten des Quantum Computing vor, während sie gleichzeitig Schutz vor Quantum-Bedrohungen bieten. ADVISORI entwickelt zukunftssichere Datenstrategien, die sowohl die Chancen als auch die Risiken der Quantum-Ära adressieren und Unternehmen einen Wettbewerbsvorsprung in der Post-Quantum-Welt verschaffen.
🔮 Quantum Computing Opportunities:
•
Quantum-Enhanced Analytics: Vorbereitung auf exponentiell beschleunigte Datenanalysen durch Quantum-Algorithmen.
•
Optimization Problems: Quantum-Lösungen für komplexe Optimierungsprobleme in Datenverarbeitung.
•
Machine Learning Acceleration: Quantum Machine Learning für revolutionäre KI-Capabilities.
•
Cryptographic Applications: Quantum-sichere Verschlüsselung für zukünftige Datensicherheit.
🛡 ️ Post-Quantum Security Preparation:
•
Quantum-Safe Cryptography: Migration zu quantenresistenten Verschlüsselungsverfahren.
•
Security Architecture Evolution: Anpassung von Sicherheitsarchitekturen an Quantum-Bedrohungen.
•
Key Management Systems: Quantum-sichere Schlüsselverwaltung für Datenarchitekturen.
•
Risk Assessment: Bewertung von Quantum-Risiken für bestehende Datenbestände.
🔧 Technical Implementation Strategies:
•
Hybrid Classical-Quantum Systems: Entwicklung von Architekturen, die klassische und Quantum Computing kombinieren.
•
Quantum Simulation: Vorbereitung durch Quantum-Simulationen und Proof-of-Concepts.
•
Algorithm Adaptation: Anpassung bestehender Algorithmen für Quantum-Umgebungen.
•
Infrastructure Planning: Langfristige Infrastrukturplanung für Quantum-Integration.
Welche ganzheitlichen Transformationsstrategien entwickelt ADVISORI für die Evolution zu AI-First Data Organizations und wie wird der kulturelle Wandel zu datengetriebenen Unternehmen gefördert?
Die Transformation zu AI-First Data Organizations erfordert einen ganzheitlichen Ansatz, der technische, organisatorische und kulturelle Aspekte umfasst. ADVISORI entwickelt umfassende Transformationsstrategien, die Unternehmen dabei unterstützen, eine datengetriebene DNA zu entwickeln und KI als strategischen Wettbewerbsvorteil zu etablieren. Unser Ansatz schafft nachhaltige Veränderungen auf allen Organisationsebenen.
🎯 AI-First Transformation Framework:
•
Strategic Vision Development: Entwicklung einer klaren Vision für die AI-First-Transformation mit messbaren Zielen.
•
Cultural Change Management: Systematischer Kulturwandel hin zu datengetriebenen Entscheidungsprozessen.
•
Organizational Restructuring: Anpassung von Organisationsstrukturen für optimale Datennutzung und KI-Innovation.
•
Skill Development: Aufbau von AI- und Data-Kompetenzen auf allen Organisationsebenen.
🚀 Technology Enablement:
•
Modern Data Stack Implementation: Aufbau moderner, AI-nativer Datenarchitekturen.
•
AI Platform Development: Entwicklung integrierter AI-Plattformen für unternehmensweite Nutzung.
•
Automation Integration: Automatisierung von Datenoperationen für erhöhte Effizienz.
•
Innovation Labs: Etablierung von Innovation Labs für kontinuierliche AI-Experimente.
🤝 Change Management Excellence:
•
Leadership Alignment: Sicherstellung des Commitments und der Unterstützung durch die Führungsebene.
•
Communication Strategy: Umfassende Kommunikationsstrategien für die Transformation.
Erfolgsgeschichten
Entdecken Sie, wie wir Unternehmen bei ihrer digitalen Transformation unterstützen
Generative KI in der Fertigung
Bosch
KI-Prozessoptimierung für bessere Produktionseffizienz
Fallstudie

Ergebnisse
Reduzierung der Implementierungszeit von AI-Anwendungen auf wenige Wochen
Verbesserung der Produktqualität durch frühzeitige Fehlererkennung
Steigerung der Effizienz in der Fertigung durch reduzierte Downtime
AI Automatisierung in der Produktion
Festo
Intelligente Vernetzung für zukunftsfähige Produktionssysteme
Fallstudie

Ergebnisse
Verbesserung der Produktionsgeschwindigkeit und Flexibilität
Reduzierung der Herstellungskosten durch effizientere Ressourcennutzung
Erhöhung der Kundenzufriedenheit durch personalisierte Produkte
KI-gestützte Fertigungsoptimierung
Siemens
Smarte Fertigungslösungen für maximale Wertschöpfung
Fallstudie

Ergebnisse
Erhebliche Steigerung der Produktionsleistung
Reduzierung von Downtime und Produktionskosten
Verbesserung der Nachhaltigkeit durch effizientere Ressourcennutzung
Digitalisierung im Stahlhandel
Klöckner & Co
Digitalisierung im Stahlhandel
Fallstudie

Ergebnisse
Über 2 Milliarden Euro Umsatz jährlich über digitale Kanäle
Ziel, bis 2022 60% des Umsatzes online zu erzielen
Verbesserung der Kundenzufriedenheit durch automatisierte Prozesse
Lassen Sie uns
Zusammenarbeiten!
Ist Ihr Unternehmen bereit für den nächsten Schritt in die digitale Zukunft? Kontaktieren Sie uns für eine persönliche Beratung.
Ihr strategischer Erfolg beginnt hier
Unsere Kunden vertrauen auf unsere Expertise in digitaler Transformation, Compliance und Risikomanagement
Bereit für den nächsten Schritt?
Vereinbaren Sie jetzt ein strategisches Beratungsgespräch mit unseren Experten
30 Minuten • Unverbindlich • Sofort verfügbar
Zur optimalen Vorbereitung Ihres Strategiegesprächs:
Ihre strategischen Ziele und Herausforderungen
Gewünschte Geschäftsergebnisse und ROI-Erwartungen
Aktuelle Compliance- und Risikosituation
Stakeholder und Entscheidungsträger im Projekt
Bevorzugen Sie direkten Kontakt?
Direkte Hotline für Entscheidungsträger
Strategische Anfragen per E-Mail
Detaillierte Projektanfrage
Für komplexe Anfragen oder wenn Sie spezifische Informationen vorab übermitteln möchten