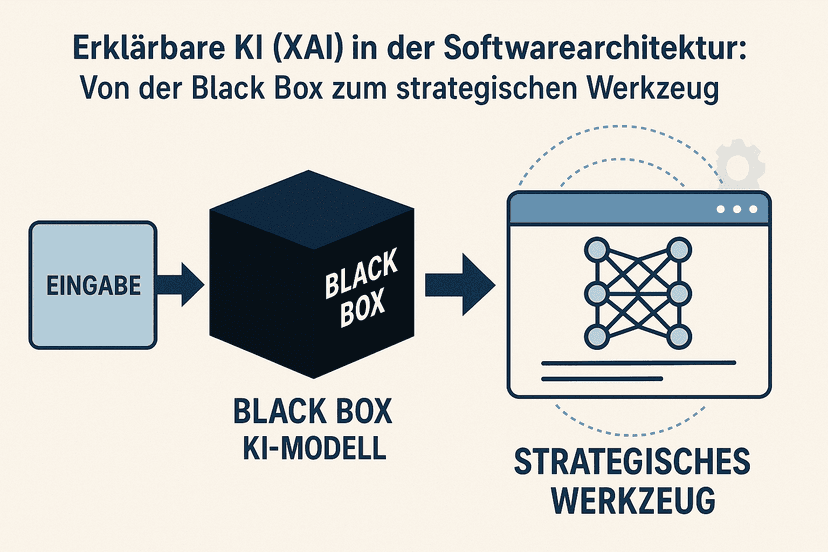
Daten zum Leben erwecken
Machine Learning
Transformieren Sie Ihre Daten in intelligente Systeme, die kontinuierlich lernen und sich verbessern. Mit unseren Machine-Learning-Lösungen entwickeln Sie lernfähige Algorithmen, die Muster in Ihren Daten erkennen, Vorhersagen treffen und komplexe Entscheidungen automatisieren. ADVISORI unterstützt Sie bei der Konzeption, Entwicklung und Implementierung maßgeschneiderter ML-Anwendungen, die messbare Geschäftswerte schaffen.
- ✓Höhere Prognosegenauigkeit durch selbstlernende Algorithmen (bis zu 90%)
- ✓Automatisierung komplexer Entscheidungsprozesse mit 70–80% Zeitersparnis
- ✓Erkennung verborgener Muster und Zusammenhänge in Ihren Daten
- ✓Kontinuierliche Verbesserung durch lernende Systeme ohne manuelle Neuprogrammierung
Ihr Erfolg beginnt hier
Bereit für den nächsten Schritt?
Schnell, einfach und absolut unverbindlich.
Zur optimalen Vorbereitung:
- Ihr Anliegen
- Wunsch-Ergebnis
- Bisherige Schritte
Oder kontaktieren Sie uns direkt:
Zertifikate, Partner und mehr...





Was ist Machine Learning und warum ist es für Unternehmen relevant?
Warum ADVISORI für Machine Learning?
- Interdisziplinäres Team aus Data Scientists, ML-Ingenieuren und Domänenexperten
- Praxiserprobte Methodik für erfolgreiche ML-Projekte mit nachweisbarem ROI
- Umfassende Expertise von klassischen ML-Techniken bis hin zu Deep Learning und GenAI
- Fokus auf verantwortungsvolle KI und ethische Aspekte des maschinellen Lernens
⚠
Expertentipp
Der Erfolg von Machine-Learning-Projekten hängt maßgeblich von der Qualität und Menge der verfügbaren Daten ab. Investieren Sie frühzeitig in Dateninfrastruktur und -qualität, bevor Sie komplexe ML-Modelle entwickeln. Beginnen Sie mit klar definierten, überschaubaren Anwendungsfällen mit hohem Geschäftswert.
ADVISORI in Zahlen
11+
Jahre Erfahrung
120+
Mitarbeiter
520+
Projekte
Wir verfolgen einen strukturierten, aber iterativen Ansatz bei der Entwicklung und Implementierung von Machine-Learning-Lösungen. Unsere Methodik stellt sicher, dass Ihre ML-Modelle sowohl technisch ausgereift als auch geschäftlich wertvoll sind und nahtlos in Ihre bestehenden Prozesse integriert werden.
Unser Vorgehen
1
Phase 1
Phase 1: Problem Definition – Präzise Formulierung des Geschäftsproblems und der ML-Ziele
2
Phase 2
Phase 2: Datenanalyse – Bewertung der Datenqualität, Exploration und Feature Engineering
3
Phase 3
Phase 3: Modellentwicklung – Training, Validierung und Optimierung von ML-Modellen
4
Phase 4
Phase 4: Integration – Einbindung in bestehende Systeme und Geschäftsprozesse
5
Phase 5
Phase 5: Monitoring & Evolution – Kontinuierliche Überwachung und Verbesserung der Modelle
"Machine Learning ist keine Zauberei, sondern eine Kombination aus Datenverständnis, algorithmischem Know-how und sorgfältiger Implementation. Der wahre Wert entsteht nicht durch den Einsatz der neuesten Algorithmen, sondern durch die intelligente Anwendung der richtigen Techniken auf gut verstandene Geschäftsprobleme und hochwertige Daten. Diese Verbindung von Data Science und Domänenwissen ist der Schlüssel zum Erfolg."

Asan Stefanski
Head of Digital Transformation
Expertise & Erfahrung:
11+ Jahre Erfahrung, Studium Angewandte Informatik, Strategische Planung und Leitung von KI-Projekten, Cyber Security, Secure Software Development, AI
Unsere Dienstleistungen
Wir bieten Ihnen maßgeschneiderte Lösungen für Ihre digitale Transformation
Predictive Modeling & Classification
Entwicklung präziser Vorhersage- und Klassifikationsmodelle, die aus historischen Daten lernen und zukünftige Ereignisse oder Kategorien mit hoher Genauigkeit prognostizieren.
- Kundensegmentierung und personalisierte Empfehlungen
- Nachfrageprognosen und Bedarfsplanung
- Risikobewertung und Betrugserkennung
- Churn-Vorhersage und Kundenbindungsmaßnahmen
Natural Language Processing & Text Analytics
Entwicklung von ML-Modellen zur Verarbeitung, Analyse und Verstehen natürlicher Sprache für Textklassifikation, Sentiment-Analyse, Informationsextraktion und automatisierte Interaktionen.
- Sentiment-Analyse und Opinion Mining
- Automatisierte Textkategorisierung und -zusammenfassung
- Intelligente Chatbots und Conversational AI
- Named Entity Recognition und Informationsextraktion
Computer Vision & Image Recognition
Entwicklung von ML-Modellen zur automatisierten Analyse, Erkennung und Interpretation visueller Daten für Objekterkennung, Bildklassifikation und visuelle Qualitätskontrolle.
- Objekterkennung und Bildklassifikation
- Optische Zeichenerkennung (OCR) und Dokumentenanalyse
- Visuelle Qualitätskontrolle und Defekterkennung
- Gesichtserkennung und biometrische Authentifizierung
ML-Plattformen & MLOps
Entwicklung und Implementierung robuster ML-Plattformen und MLOps-Prozesse für die effiziente Entwicklung, Bereitstellung und kontinuierliche Verbesserung von Machine-Learning-Modellen.
- Aufbau skalierbarer ML-Plattformen für Modellentwicklung
- Implementierung von MLOps-Prozessen und CI/CD-Pipelines
- Automatisiertes Modell-Monitoring und Performance-Tracking
- Governance-Frameworks für verantwortungsvolle KI-Nutzung
Unsere Kompetenzen im Bereich Advanced Analytics
Wählen Sie den passenden Bereich für Ihre Anforderungen
Big Data Solutions
Große Datenmengen strategisch nutzen: Wir konzipieren und implementieren Big-Data-Plattformen, die strukturierte und unstrukturierte Daten vereinen — von Data Lakes über Echtzeit-Pipelines bis zur KI-Integration. Mit unseren Big-Data-Lösungen bew�ltigen Sie die Herausforderungen exponentiell wachsender Datenvolumen und erschließen deren verborgenes Potenzial.
Predictive Analytics
Transformieren Sie Ihre historischen Daten in präzise Vorhersagen über zukünftige Entwicklungen und Trends. Mit unseren Predictive-Analytics-Lösungen erschließen Sie verborgene Zusammenhänge in Ihren Daten und treffen proaktive Entscheidungen mit höchster Treffsicherheit. Wir unterstützen Sie bei der Entwicklung und Implementierung maßgeschneiderter Prognosemodelle, die Ihre spezifischen Geschäftsanforderungen optimal abbilden.
Prescriptive Analytics
Transformieren Sie Prognosen in konkrete Handlungen und optimale Entscheidungen. Mit unseren Prescriptive-Analytics-Lösungen gehen Sie über das "Was wird passieren?" hinaus und beantworten die Frage "Was sollten wir tun?". Wir unterstützen Sie bei der Entwicklung intelligenter Systeme, die nicht nur Zukunftsprognosen liefern, sondern auch optimale Handlungsalternativen identifizieren und komplexe Entscheidungsprozesse teilweise oder vollständig automatisieren.
Real-time Analytics
Transformieren Sie kontinuierliche Datenströme in sofortige Erkenntnisse und Handlungen. Mit unseren Real-time-Analytics-Lösungen analysieren Sie Daten im Moment ihrer Entstehung, erkennen kritische Ereignisse unmittelbar und reagieren proaktiv auf sich ändernde Bedingungen. Wir unterstützen Sie bei der Implementierung leistungsfähiger Echtzeit-Analysesysteme, die Ihre Reaktionsfähigkeit revolutionieren und Ihnen entscheidende Wettbewerbsvorteile verschaffen.
Häufig gestellte Fragen zur Machine Learning
Was ist Machine Learning und wie unterscheidet es sich von klassischer KI?
Machine Learning (maschinelles Lernen) ist ein Teilbereich der Künstlichen Intelligenz, bei dem Algorithmen aus Daten lernen und sich selbstständig verbessern — ohne explizit für jede Aufgabe programmiert zu werden. Anders als regelbasierte KI-Systeme erkennen ML-Modelle eigenständig Muster in Daten und treffen darauf basierend Vorhersagen. Die drei Hauptkategorien sind Supervised Learning (überwachtes Lernen), Unsupervised Learning (unüberwachtes Lernen) und Reinforcement Learning (bestärkendes Lernen).
Welche Vorteile bietet Machine Learning für Unternehmen?
Machine Learning bietet Unternehmen messbare Vorteile: Prognosegenauigkeit von bis zu 90% bei Nachfragevorhersagen, 70–80% Zeitersparnis durch Automatisierung komplexer Entscheidungsprozesse, 20–30% Steigerung der operativen Effizienz und 15–25% höhere Umsätze durch personalisierte Empfehlungen. Typische Anwendungsfälle sind Predictive Maintenance, Betrugserkennung, Demand Forecasting, Qualitätskontrolle und Prozessoptimierung.
Wie läuft ein Machine-Learning-Projekt ab?
Ein ML-Projekt durchläuft fünf Phasen: 1) Problemdefinition und Use-Case-Identifikation, 2) Datenanalyse und Feature Engineering, 3) Modellentwicklung mit Training und Validierung, 4) Integration und Deployment in bestehende Systeme, 5) Monitoring und Evolution mit kontinuierlicher Überwachung und Nachtraining. ADVISORI begleitet alle Phasen mit einem agilen, iterativen Ansatz.
Was kostet eine Machine Learning Beratung?
Die Kosten variieren je nach Projektumfang: Ein Proof-of-Concept startet im niedrigen fünfstelligen Bereich, produktionsreife ML-Modelle kosten 30.000–150.000EUR je nach Komplexität. Entscheidend für den ROI sind die richtige Use-Case-Auswahl und die Datenqualität. ADVISORI bietet eine kostenfreie Erstberatung zur Potenzialermittlung.
Welche Daten brauche ich für ein Machine-Learning-Projekt?
Die Datenanforderungen hängen vom Anwendungsfall ab. Für Supervised Learning benötigen Sie gelabelte Trainingsdaten — mindestens einige hundert bis tausend Beispiele pro Kategorie. Für Unsupervised Learning reichen oft unstrukturierte Daten. Entscheidend sind Datenqualität (Vollständigkeit, Konsistenz, Aktualität), ausreichendes Datenvolumen und sauberes Feature Engineering.
Was ist der Unterschied zwischen Machine Learning und Deep Learning?
Deep Learning ist ein spezialisierter Teilbereich des Machine Learning mit tiefen neuronalen Netzen. Klassisches ML (z.B. Random Forest, SVM) arbeitet mit manuell erstellten Features und eignet sich für strukturierte Daten. Deep Learning lernt Features automatisch aus Rohdaten und eignet sich für Bild-/Spracherkennung und NLP. Bei tabellarischen Daten ist klassisches ML oft effizienter und interpretierbarer.
Wie lange dauert die Implementierung einer Machine-Learning-Lösung?
Die Zeitrahmen variieren: Proof-of-Concept 4–8 Wochen, produktionsreifes ML-Modell 3–6 Monate, vollständige ML-Plattform mit MLOps 6–12 Monate. Die Datenaufbereitung macht meist 60–80% des Aufwands aus. ADVISORI empfiehlt einen agilen, iterativen Ansatz mit schnellem erstem Proof-of-Value.
Erfolgsgeschichten
Entdecken Sie, wie wir Unternehmen bei ihrer digitalen Transformation unterstützen
Generative KI in der Fertigung
Bosch
KI-Prozessoptimierung für bessere Produktionseffizienz
Fallstudie

Ergebnisse
Reduzierung der Implementierungszeit von AI-Anwendungen auf wenige Wochen
Verbesserung der Produktqualität durch frühzeitige Fehlererkennung
Steigerung der Effizienz in der Fertigung durch reduzierte Downtime
AI Automatisierung in der Produktion
Festo
Intelligente Vernetzung für zukunftsfähige Produktionssysteme
Fallstudie

Ergebnisse
Verbesserung der Produktionsgeschwindigkeit und Flexibilität
Reduzierung der Herstellungskosten durch effizientere Ressourcennutzung
Erhöhung der Kundenzufriedenheit durch personalisierte Produkte
KI-gestützte Fertigungsoptimierung
Siemens
Smarte Fertigungslösungen für maximale Wertschöpfung
Fallstudie

Ergebnisse
Erhebliche Steigerung der Produktionsleistung
Reduzierung von Downtime und Produktionskosten
Verbesserung der Nachhaltigkeit durch effizientere Ressourcennutzung
Digitalisierung im Stahlhandel
Klöckner & Co
Digitalisierung im Stahlhandel
Fallstudie

Ergebnisse
Über 2 Milliarden Euro Umsatz jährlich über digitale Kanäle
Ziel, bis 2022 60% des Umsatzes online zu erzielen
Verbesserung der Kundenzufriedenheit durch automatisierte Prozesse
Lassen Sie uns
Zusammenarbeiten!
Ist Ihr Unternehmen bereit für den nächsten Schritt in die digitale Zukunft? Kontaktieren Sie uns für eine persönliche Beratung.
Ihr strategischer Erfolg beginnt hier
Unsere Kunden vertrauen auf unsere Expertise in digitaler Transformation, Compliance und Risikomanagement
Bereit für den nächsten Schritt?
Vereinbaren Sie jetzt ein strategisches Beratungsgespräch mit unseren Experten
30 Minuten • Unverbindlich • Sofort verfügbar
Zur optimalen Vorbereitung Ihres Strategiegesprächs:
Ihre strategischen Ziele und Herausforderungen
Gewünschte Geschäftsergebnisse und ROI-Erwartungen
Aktuelle Compliance- und Risikosituation
Stakeholder und Entscheidungsträger im Projekt
Bevorzugen Sie direkten Kontakt?
Direkte Hotline für Entscheidungsträger
Strategische Anfragen per E-Mail
Detaillierte Projektanfrage
Für komplexe Anfragen oder wenn Sie spezifische Informationen vorab übermitteln möchten