

Wie kann Generative KI dabei helfen, die Herausforderungen in der Validierung von Risikomodellen bei Banken zu bewältigen?
Im ersten von zwei Artikeln über den Einsatz von Generativer KI in der Validierung von Risikomodellen bei Finanzinstituten haben wir die wesentlichen Herausforderungen der Validierung sowie die Rahmenbedingungen für den Einsatz von KI beleuchtet. In diesem Artikel betrachten wir konkrete Anwendungsfälle und die daraus resultierenden Implikationen.
Anwendungsfälle
Die Validierung umfasst den gesamten Prozess der Datenaufbereitung und Überprüfung. Sie reicht von der Prüfung der Trennschärfe bis hin zur prozessorientierten Validierung. Das folgende Schaubild zeigt die verschiedenen Aspekte eines Validierungsprozesses. Diese Aspekte dienen als Grundlage für die Überprüfung der Anwendung von Generativer KI.
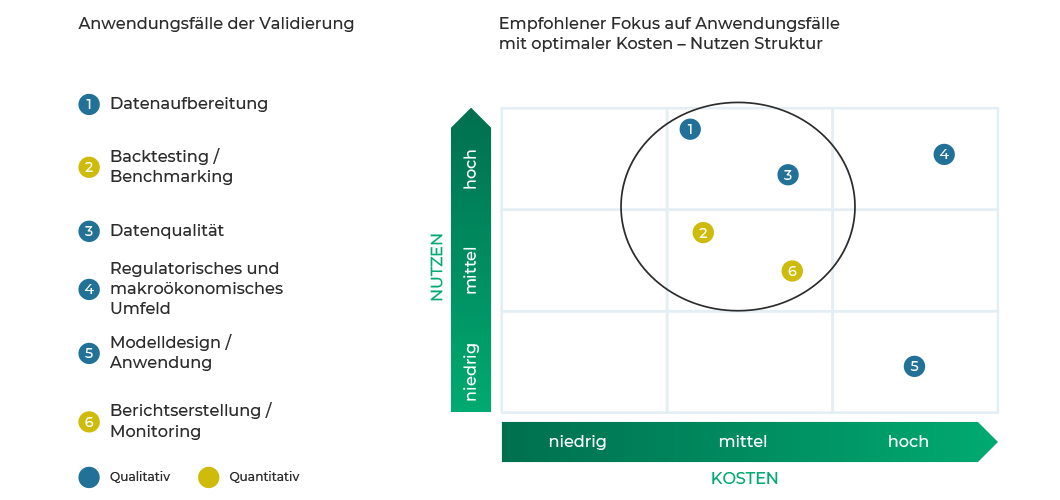
Abbildung 1: Anwendungsbereiche der Generativen KI in der Validierung eines Risikoklassifizierungsmodells
Im Folgenden wird die Anwendung Generativer KI in den oben genannten Validierungsaspekten erörtert und insbesondere auf die Anwendungsfälle mit optimaler Kosten-Nutzen-Struktur gemäß Abbildung 1 eingegangen. Um die Studie etwas konkreter zu gestalten, wird dabei der Fokus auf die Validierung eines Kreditrisikoklassifizierungsverfahrens gelegt.
I. Datenaufbereitung
Eine gute und umfangreiche historische Datenlage bildet die Grundlage für die Entwicklung eines hochwertigen Ratingsystems. Die Qualität der für die Entwicklung eines Ratingverfahrens relevanten Daten ist somit von enormer Bedeutung. Die Beschaffung und Integration relevanter Daten sowie die Sicherstellung der Datenqualität stellen vor dem Hintergrund begrenzter personeller, finanzieller und technischer Ressourcen oft eine große Herausforderung dar.
Ein wichtiger Schwerpunkt bei der Datenaufbereitung ist es, sicherzustellen, dass unvollständige, fehlerhafte oder inkonsistente Daten keine verzerrten Ergebnisse verursachen. Solche Verzerrungen könnten die Validität der Analyse und die Nutzung des betrachteten Ratingsystems beeinträchtigen. Daher ist es die zentrale Aufgabe des Validierers, Anomalien in den Daten zu erkennen und zu bereinigen. Dieser Bereinigungsprozess kann jedoch oft sehr zeitaufwendig, komplex und nicht immer erfolgreich sein.
Der Einsatz von Generativer KI ermöglicht es, effizient Inkonsistenzen in den Daten zu erkennen und synthetische Daten zu erzeugen. Diese bieten eine bessere Basis für die Validierung der Risikomodelle. Generative KI ermöglicht die Erstellung von Risikomodellen: Diese lernen, was “normale” Daten ausmacht und können daher proaktiv Abweichungen von dieser Norm erkennen. Dadurch wird die Zuverlässigkeit der Risikomodelle erhöht und potenzielle Risiken frühzeitig erkannt.
Die Schaffung synthetischer Daten durch Generative KI-Modelle kann hier von entscheidender Bedeutung sein. Diese synthetischen Daten ermöglichen es, realistische Testszenarien zu erstellen, ohne dabei Anforderungen an Datenschutz und Informationssicherheit (bspw. DSGVO oder ISMS)zu verletzen.
Automatisierte Validierungsregeln allein können nicht alle Nuancen von Datenanomalien erfassen. Durch die Einbindung von Fachexperten in den Validierungsprozess wird jedoch die Möglichkeit geschaffen, komplexe Probleme zu identifizieren, die automatisierte Systeme möglicherweise übersehen.
Generative KI hilft, indem sie synthetische Daten erzeugt, die für Diskussionen und Analysen verwendet werden können. Diese synthetischen Daten gleichen unausgewogene Datensätze aus, indem sie zusätzliche Proben erzeugen, um das Trainingsset zu vervollständigen. Das verbessert die Genauigkeit von Klassifizierungsmodellen und führt zu fundierteren Risikoanalysen.
Durch die Erzeugung synthetischer Daten können Banken teilweise den teuren Prozess der Datensammlung und -beschriftung reduzieren. Dies spart Kosten und beschleunigt den Validierungsprozess, da weniger Zeit für die Beschaffung und Bereinigung von Daten benötigt wird.
II. Quantitative Validierung
Unter quantitativer Validierung verstehen wir im Wesentlichen die Überprüfung der Prognosegüte, Trennschärfe und Stabilität eines modellgestützten Ratingverfahrens anhand mathematisch-statistischer Verfahren auf Basis von historischen Daten. In diesem Kapitel wird auf die Nutzung der erstellten synthetischen Daten (siehe Abschnitt Datenaufbereitung) und deren Mehrwert eingegangen.
Backtesting / Benchmarking
Traditionelle Ansätze stoßen bei Backtesting oft an Grenzen, da historische Ausfälle (bspw. Low-Default-Portfolio¹) möglicherweise unzureichend sind. Alternativ werden u. a.² externe Daten herangezogen, um im Rahmen eines Benchmarkings ein aussagekräftiges Backtesting durchführen zu können. Ziel ist es, interne Daten mit externen Datensätzen zu ergänzen, um darauf basierend Validierungsanalysen vorzunehmen. Oft stehen jedoch Institute vor der Herausforderung, gute repräsentative Daten zu finden, was ein wesentliches regulatorisch vorgegebenes Kriterium darstellt, um eine aussagekräftige Validierung durchführen zu können.
In der Praxis wird klar, dass es bei KI-Anwendungen nicht in erster Linie darum geht, das perfekte KI-Modell zu entwickeln, sondern vielmehr darum, systematisch und algorithmisch den besten Datensatz zu erstellen, um ein bestimmtes Modell damit anzureichern. Dieser Ansatz heißt Datenzentrierte-KI³ und ist mittlerweile unerlässlich, um Systeme zuverlässig zu trainieren. GAN-Modelle und LLMs können in der Validierung helfen, indem sie auf Basis externer Daten neue, repräsentative und damit plausiblere Daten erzeugen. Durch den Einsatz solcher KI-Modelle können Banken ein breiteres Spektrum von Szenarien generieren, die potenzielle Schwachstellen ihrer Risikomodelle aufdecken, welche durch traditionelle Ansätze möglicherweise nicht erfasst werden.
III. Qualitative Validierung
Die qualitative Validierung soll die statistischen Untersuchungen ergänzen und umfasst im Wesentlichen vier Aspekte:
- das Design des Ratingsystems,
- die Datenqualität,
- die interne Verwendung des Ratingverfahrens sowie
- die Entwicklungen zum Umfeld des Ratingverfahrens.
Datenqualität
Wie in dem Abschnitt Datenaufbereitung detailliert beschrieben, setzt ein angemessenes Ratingverfahren eine solide Datengrundlage voraus. In der Überprüfung der Datenqualität wird der Umgang mit den Daten untersucht und bewertet. Konkret geht es darum zu bewerten, wie bspw. fehlende Daten, Duplikate oder sonstige Datenanomalien behandelt wurden. In der Praxis werden oft Datenprüfungsregeln standardisiert und automatisiert und deren Ergebnis als Tabelle im finalen Bericht dargestellt.
Effiziente Methoden zur Überprüfung von Anomalien können schon während der Datenaufbereitung angewendet werden. Wenn Generative KI bereits während der Datenaufbereitung eingesetzt wird, wird die spätere Bewertung der Datenqualität in der Validierungsphase erheblich vereinfacht.
Umfeld
Unter dieser Kategorie wird üblicherweise der Ausblick zu den regulatorischen Anforderungen und makroökonomischen Einflussfaktoren zusammengefasst. Üblicherweise werden neue relevante regulatorische Anforderungen und makroökonomische Aspekte identifiziert, gesammelt und in den Bericht aufgenommen. Allerdings wird diese Aufgabe in der Praxis großenteils manuell vorgenommen.
Generative KI kann diesen Prozess automatisieren, indem sie verschiedene Eingabeformate verarbeitet, um die gewünschte Übersicht zu erstellen. Der aktuelle Entwicklungsstand der KI-Modelle ermöglicht jedoch noch nicht die Verarbeitung großer Datenmengen. Daher ist Generative KI derzeit noch keine vollständige Lösung für dieses Problem, siehe Abschnitt Reporting und Monitoring.
Modelldesign und Anwendung
Für modellgestützte Ratingverfahren spielt die Überprüfung des Modelldesigns eine wichtige Rolle, insbesondere bei Modellen mit einer quantitativen Validierung basierend auf einer sehr eingeschränkten Datenlage (siehe Abschnitt Datenqualität). Der Prozess der Ratingvergabe und der Einfluss der Ratingfaktoren sollen u. a. überprüft werden.
Darüber hinaus ist die tatsächliche Verwendung der Ratingergebnisse im bankinternen Risikomanagement und Reporting zu überprüfen. Anwendungsbeispiele sind ratingbasierte Kreditentscheidungen und eine Kreditrisikostrategie basierend auf Bonitätsstufen.
In der Praxis wird diese Überprüfung oft durch eine tiefergehende Analyse des Modells und des Prozesses sowie die Sammlung und Bewertung des Feedbacks der Anwender des Ratingverfahrens vorgenommen. Ein Austausch mit den relevanten Beteiligten ist daher unerlässlich. Dieser Prozess ist überwiegend manuell und erfordert damit je nach Größe des Portfolios und Komplexität des Modells einen nicht geringen Aufwand.
Bei Ratingverfahren mit Möglichkeit der Überschreibung, muss nach der Beschreibung eine Begründung erfasst werden, die in der Validierung bewertet werden muss. Im Falle eines frei formulierten Textes, kann Generative KI helfen, die Begründungen einzuordnen und zu bewerten.
Eine Nutzung Generativer KI in diesem Arbeitsschritt ist jedoch nur bedingt zu empfehlen, da der Trainingsaufwand für eine ausreichende Performance zu hoch wäre.
IIII. Validierungsreport und Monitoring
Der Validierungsbericht bildet üblicherweise das zentrale Medium, um die Ergebnisse der Validierung innerhalb der Bank und extern an den Wirtschaftsprüfer bzw. die Bankenaufsicht zu kommunizieren. Banken fahren unterschiedliche Ansätze, um den Report in optimaler Weise zu erstellen. Während einige Institute bereits einen möglichst gut automatisierten Prozess von der Integration der Ergebnisse aus den Auswertungen bis zur Interpretation und Kommentierung haben, kämpfen die meisten Institute noch mit sehr vielen manuellen Prozessen, die sehr viele Ressourcen binden und zugleich fehleranfällig sind.
Eine Automatisierung des vollen Prozesses hat sich bisher als sehr schwierig erwiesen, da die Interpretation der Ergebnisse und deren Kommentierung im Bericht nur bedingt maschinell durchführbar ist. Für die Automatisierung solcher Prozesse eignen sich multimodale Modelle sehr gut.
Multimodale Modelle sind in der Lage, über mehrere Inputformate hinweg Outputs zu generieren. Dabei kann generative KI mit den Inputdaten für den Bericht (Metriken, Reports, Codes) angereichert werden und würde den gewünschten Outputbericht erzeugen. Das verwendete Modell kann für die explizite Struktur und Sprache des Validierungsberichts über das Finetuning optimiert werden. Dabei werden dem KI-Modell in einem iterativen Prozess historische Inputdaten und die entsprechenden gewünschten Outputberichte vorgelegt, sodass sich das Modell entsprechend anpassen kann. Diese spezialisierte Anpassung ermöglicht es der KI, relevante und präzise Inhalte zu generieren, die den spezifischen internen und aufsichtlichen Anforderungen entsprechen. Durch diese Technik können die Berichte nicht nur schneller erstellt, sondern auch hinsichtlich ihrer Qualität und Compliance konsistenter überwacht werden. Dies trägt zusätzlich dazu bei, die Integrität sowie Verlässlichkeit der Validierungsreporterstellung zu stärken. Des Weiteren würde sich eine automatische Ableitung von Handlungsempfehlungen mit der entsprechenden Kritikalität anbieten.
Die Visualisierung zielgruppenspezifischer Ergebnisse inkl. Ad-Hoc-Anfragen wäre damit einfach und ohne großen Aufwand umzusetzen.
Es ist allerdings wichtig zu betonen, dass generative KI laut dem aktuellen Stand der Entwicklung hinsichtlich der Größe von Inputdaten noch sehr eingeschränkt ist. Für weniger umfangreiche Validierungen und kleinere Portfolien würde sich diese Lösung gut anbieten.
Implikationen
Die Implementierung generativer KI in die Validierung von Risikomodellen bei Banken ist eine Möglichkeit, bestimmte Teile des Validierungsprozesses effizienter und effektiver zu gestalten. Jedoch sind damit auch Herausforderungen verbunden, die nicht außer Acht gelassen werden sollten:
- Komplexität der Modelle: Generative KI-Modelle sind oft sehr komplex und schwer zu interpretieren. Dies kann es schwierig machen, die Ergebnisse der Modelle zu verstehen.
- Regulatorische Konformität: Banken müssen sicherstellen, dass die Verwendung von generativen KI-Modellen in der Validierung und in angrenzenden Modelllebensphasen den stets wachsenden regulatorischen Anforderungen entspricht. Dies kann zusätzliche Komplexität und Kosten mit sich bringen.
- IT-Risiko: Lokale Modelle, die auf dedizierten Servern betrieben werden, bieten eine Möglichkeit zur Sicherstellung der Datenkontrolle, bergen jedoch das potenzielle Risiko einer Infektion durch versteckte Malware. Im Kontrast dazu können externe Modelle, die über APIs zugänglich sind, das Malware-Risiko reduzieren, jedoch Datenschutzbedenken aufwerfen, da sie potenziell die Offenlegung sensibler Daten an Drittanbieter mit sich bringen. Das nachfolgende Schaubild illustriert gut die Problematik mit den daraus resultierenden Implikationen.
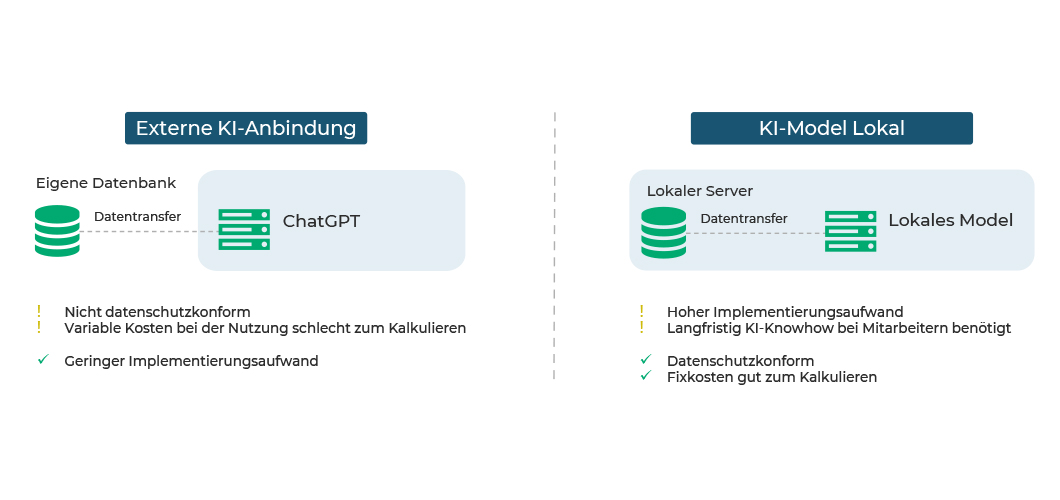
Abbildung 2: Anbindung eines KI-Modells: extern vs. lokal
- Mitarbeiter Knowhow: Die Leistung der eingesetzten KI-Modelle kann im Laufe der Zeit nachlassen, da sie veralten können oder die Präzision der Ergebnisse aufgrund struktureller Veränderungen der Inputdaten abnehmen kann. Um angemessen auf solche Probleme und Anpassungen reagieren zu können, ist es wichtig, Mitarbeiter langfristig in KI- und Softwaretechnik zu schulen. In der Praxis wird die Implementierung und Wartung von KI-Systemen oft als “MLOps” (Machine Learning Operations) bezeichnet.
- Vertrauen und Transparenz: Das Vertrauen der Stakeholder kann beeinträchtigt werden, da die Modelle oft schwer verständlich sind. Es ist daher wichtig, Transparenz und Erklärbarkeit in den Modellen sicherzustellen, um das Vertrauen zu stärken.
Angesichts der aufgelisteten Herausforderungen empfehlen wir die Kosten und Risiken über die Validierungsaufgaben hinaus zu betrachten, um ein ganzheitliches Bild als Grundlage für die Entscheidung zu berücksichtigen.
Die Umsetzung eines kleinen Use Cases erlaubt eine praktische Beurteilung der Implikationen basierend auf den institutsspezifischen Gegebenheiten. Anschließend kann eine fundierte Roadmap für die weitere Nutzung von KI in der Modellrisikovalidierung erstellt werden. Basierend auf den Ergebnissen der Analyse der Fokus-Anwendungsfälle (siehe Abbildung 1) ist die Datenaufbereitung besonders gut geeignet für die Durchführung des Use Cases. Ergänzend dazu zeigt sich die Anwendung generativer KI in der Datenaufbereitung in einigen weiteren Fokus-Anwendungsbereichen (Backtesting/Benchmarking und Datenqualität).
Wie kann ADVISORI Sie unterstützen?
ADVISORI berät Kunden bereits seit Jahren zum Thema Risikomodellierung und Validierung bei Banken. Nachdem das Thema Generative Künstliche Intelligenz in den Fokus von nationalen wie internationalen Regulatoren gerückt ist und für Investoren bzw. Stakeholder im Bankenumfeld von enormer Bedeutung geworden ist, beschäftigt sich ADVISORI u. a. mit der Anwendung Generativer KI auf das Modellrisikomanagement.
Kontaktieren Sie uns unter: www.advisori.de/kontakt
1) Ein Low-Default-Portfolio ist ein Portfolio, das hauptsächlich mit Fazilitäten mit einem niedrigen Ausfallrisiko besteht, wie bspw. Großfirmenkunden.
2) Ein weiterer Ansatz im Falle von wenigen historischen Ausfalldaten ist die Untersuchung der Häufigkeitsverteilung weiterer Risikomerkmalen, wie bspw. der 30-Tage-Verzug.
3 Für detaillierte Informationen hierzu sei auf die folgende Webseite verwiesen: https://dcai.csail.mit.edu/



